shell 数组循环的用法,对于一些构建工具很有帮助
1 | #!/bin/bash |
使用shell做服务器的健康检查脚本#
1 | # health.sh |
shell 数组循环的用法,对于一些构建工具很有帮助
1 | #!/bin/bash |
1 | # health.sh |
高效的团队往往会充分利用不同的工具来提升自己的工作效率,譬如通过钉钉进行沟通协同,使用 Trello 进行任务管理,使用 GitLab 或者 GitHub 来进行代码管理,使用 JIRA 来进行项目与事务跟踪等等。不同的工具分工合作,把团队的事务数字化管理流转起来,并在一定程度上实现了流程的自动化,将大家从一些繁琐的事务中解放出来,有效地提升了大家的协同能力和工作质量。
本文来讨论一下利用 node 接入机器人来实现一些日常办公小功能的自动化。
什么是群机器人?群机器人是钉钉群的高级扩展功能。群机器人可以将第三方服务的信息聚合到群聊中,实现自动化的信息同步。
首先来看一下案例:
博客机器人,cicd 触发时将新文章推送到群
bug 提醒,每天定时推送现有 bug 到群
首先打开钉钉群右上角,点群设置。找到智能群助手,点击添加机器人。
这里要选择自定义机器人,安全策略要选择加签。
这里我们拿到密钥,点击继续,拿到机器人的 webhook。
关于签名的算法
1 | const crypto = require('crypto'); |
本质上是我们向钉钉的 openAPI 发送一个 post 请求。只要我们拿到正确的 url 和请求格式,就可以向机器人发送消息。这样就完成了钉钉机器人的接入。
消息类型及数据格式
1 | const axios = require('axios'); |
在 cicd 中配置在build的时候执行脚本,找出新增文章推送到群。
主要问题在于如何找出新的文章。
在构建时,会临时生成 db.json 文件,这个文件不会被push,部署时会被删除。我们可以每次构建时保存一份文章列表,一起推送到git上面去。这样我们每次构建完成后,部署之前,先读取旧的文章名单,然后再读取 db.json,对比找出新的文章。
每篇文章我们要生成摘要,方法是:找到第一个 markdown 的 ## 标记,将标题后面的文章的第一句话当作摘要。所以希望大家尽量要写 ## 标记。
1 | // 旧的文章list |
目的是实现从禅道拉去 bug 清单,过滤出特定人员,发送到指定群。未来todo要实现能单独@机器人,他会把属于你的bug发给你。
难点在于如何从禅道拉取 bug 清单。禅道不是 Restful 的,他是用后端模板渲染的 html 返回的方式。要解决的问题是,模拟登录和拉取数据。
这里采用的方案是使用 puppeteer 包,作用是生成一个无头的浏览器,这样就可以操作DOM元素了。
puppeteer文档
1 | // 模拟登录禅道 |
希望这篇文章能给大家带来启发,不仅仅是机器人,大家都能搭建适合自己的自动化脚本。社会发展就是机器取代人,简单重复的工作被取代。而我们人最重要的一点,就是机器没有的思维。发动我们聪明绝顶的脑袋想一想,集思广益,助飞效能提升。
这篇文章写给一个姓港的同学,希望他能学会基本的ngx使用,然后再去实现自己的想法
启动 ngx 并关联 80 端口
1 | docker run -d -p 80:80 --name nginx nginx:latest |
进入容器,这个控制台留着刷新NGX配置使用
1 | docker exec -it nginx bash |

查询 docker ngx 的文档可知,配置文件在 /etc/nginx/conf.d/default.conf, 新增一个控制台,将docker里面的ngx配置文件拷贝出来进行调整
1 | docker cp nginx:/etc/nginx/conf.d/default.conf ./default.conf |
进行ngx的配置修改,然后将文件拷贝回去(下面这段配置是简单地一个代理)
1 | server { |
进行拷贝
1 | docker cp ./default.conf nginx:/etc/nginx/conf.d/default.conf |
在容器里面执行命令
1 |
|
可以通过 http://localhost/user/d3a1a93e2d572937d7708b55d660bf46.png 查看效果
可以测试一下下列两个图片的展示情况

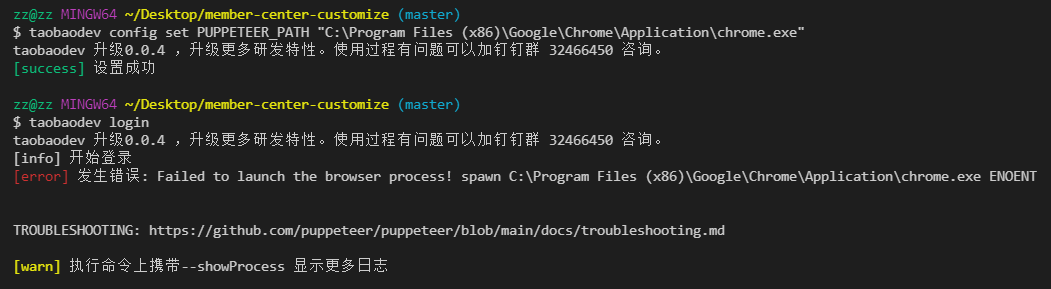
taobaodev 一款基于命令行的淘宝小程序研发工具。taobaodev提供了便捷的研发功能,使用自己喜欢的IDE + 浏览器就可以完成小程序的研发调试,预览,上传等操作。
由于命令行借助浏览器的相关能力,所以需要本机安装chrome,如果chrome不在默认安装路径上,需要进行指定。
1 |
|
taobaodev upload –appId=3000000006501031
转载自 https://mp.weixin.qq.com/s/s5KrA8p-vgamKKmRjchgig
具体到实处,则可以从用户体验和资源分配这两个方面说起。
与前端JavaScript在单线程上执行,而且它还与UI渲染共用一个线程一样。JavaScript在执行的时候UI渲染和响应是处于停滞状态的。那么,在node中,假设此时不使用异步io,那么当一个io在执行的时候,另一个io的执行必须等待前一个io执行完毕才可以。那么速度就会慢很多,需要认识到只有后端能够快速响应资源,才能让前端的体验变好。
我们首先需要知道计算机在发展过程中将组件进行了抽象,分为I/O设备和计算设备。
如果创建多线程的开销小于并行执行,那么多线程的方式是首选的。多线程的代价在于创建线程和执行期线程上下文切换的开销较大。另外,在复杂的业务中,多线程编程经常面临锁、状态同步等问题,这是多线程被诟病的主要原因。但是多线程在多核CPU上能够有效提升CPU的利用率,这个优势是毋庸置疑的。
单线程顺序执行任务的方式比较符合编程人员按顺序思考的思维方式。它依然是最主流的编程方式,因为它易于表达。但是串行执行的缺点在于性能,任意一个略慢的任务都会导致后续执行代码被阻塞。在计算机资源中,通常I/O与CPU计算之间是可以并行进行的。但是同步的编程模型导致的问题是,I/O的进行会让后续任务等待,这造成资源不能被更好地利用。
单线程同步编程模型会因阻塞I/O导致硬件资源得不到更优的使用。多线程编程模型也因为编程中的死锁、状态同步等问题让开发人员头疼。
Node在两者之间给出了它的方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步I/O,让单线程远离阻塞,以更好地使用CPU。
异步I/O可以算作Node的特色,因为它是首个大规模将异步I/O应用在应用层上的平台,它力求在单线程上将资源分配得更高效。为了弥补单线程无法利用多核CPU的缺点,Node提供了类似前端浏览器中WebWorkers的子进程,该子进程可以通过工作进程高效地利用CPU和I/O。
异步I/O的提出是期望I/O的调用不再阻塞后续运算,将原有等待I/O完成的这段时间分配给其余需要的业务去执行。
下图为异步I/O的调用示意图。

异步与非阻塞听起来似乎是同一回事。从实际效果而言,异步和非阻塞都达到了我们并行I/O的目的。但是从计算机内核I/O而言,异步/同步和阻塞/非阻塞实际上是两回事。
操作系统内核对于I/O只有两种方式:阻塞与非阻塞。在调用阻塞I/O时,应用程序需要等待I/O完成才返回结果,如图所示。

阻塞I/O的一个特点是调用之后一定要等到系统内核层面完成所有操作后,调用才结束。以读取磁盘上的一段文件为例,系统内核在完成磁盘寻道、读取数据、复制数据到内存中之后,这个调用才结束。
阻塞I/O造成CPU等待I/O,浪费等待时间,CPU的处理能力不能得到充分利用。为了提高性能,内核提供了非阻塞I/O。非阻塞I/O跟阻塞I/O的差别为调用之后会立即返回,如图所示。

这个让我想起直接打印状态为pending的promise对象,也是可以打印出来的,这个就是异步吧,虽然状态还没变为resolved或者rejected,也一样返回了。
非阻塞I/O返回之后,CPU的时间片可以用来处理其他事务,此时的性能提升是明显的。
层期望的数据,而仅仅是当前调用的状态。为了获取完整的数据,应用程序需要重复调用I/O操作来确认是否完成。这种重复调用判断操作是否完成的技术叫做轮询。
任意技术都并非完美的。阻塞I/O造成CPU等待浪费,非阻塞带来的麻烦却是需要轮询去确认是否完全完成数据获取,它会让CPU处理状态判断,是对CPU资源的浪费。
轮询技术主要包括这几种:read、select、poll、epoll。
它是最原始、性能最低的一种,通过重复调用来检查I/O的状态来完成完整数据的读取。在得到最终数据前,CPU一直耗用在等待上。下图为通过read进行轮询的示意图。

select。
它是在read的基础上改进的一种方案,通过对文件描述符上的事件状态来进行判断。下图为通过select进行轮询的示意图。

select轮询具有一个较弱的限制,那就是由于它采用一个1024长度的数组来存储状态,所以它最多可以同时检查1024个文件描述符。
poll。
该方案较select有所改进,采用链表的方式避免数组长度的限制,其次它能避免不需要的检查。但是当文件描述符较多的时候,它的性能还是十分低下的。下图为通过poll实现轮询的示意图,它与select相似,但性能限制有所改善。

epoll。
该方案是Linux下效率最高的I/O事件通知机制,在进入轮询的时候如果没有检查到I/O事件,将会进行休眠,直到事件发生将它唤醒。它是真实利用了事件通知、执行回调的方式,而不是遍历查询,所以不会浪费CPU,执行效率较高。下图为通过epoll方式实现轮询的示意图。

轮询技术满足了非阻塞I/O确保获取完整数据的需求,但是对于应用程序而言,它仍然只能算是一种同步,因为应用程序仍然需要等待I/O完全返回,依旧花费了很多时间来等待。等待期间,CPU要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。结论是它不够好。
有啊。
我们期望的完美的异步I/O应该是应用程序发起非阻塞调用,无须通过遍历或者事件唤醒等方式轮询,可以直接处理下一个任务,只需在I/O完成后通过信号或回调将数据传递给应用程序即可

幸运的是,在Linux下存在这样一种方式,它原生提供的一种异步I/O方式(AIO)就是通过信号或回调来传递数据的。
但不幸的是,只有Linux下有,而且它还有缺陷——AIO仅支持内核I/O中的O_DIRECT方式读取,导致无法利用系统缓存。
现实比理想要骨感一些,但是要达成异步I/O的目标,并非难事。前面我们将场景限定在了单线程的状况下,多线程的方式会是另一番风景。通过让部分线程进行阻塞I/O或者非阻塞I/O加轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将I/O得到的数据进行传递,这就轻松实现了异步I/O(尽管它是模拟的),示意图如图。

另一个需要强调的地方在于我们时常提到Node是单线程的,这里的单线程仅仅只是JavaScript执行在单线程中罢了。在Node中,无论是*nix还是Windows平台,内部完成I/O任务的另有线程池。
完成整个异步I/O环节的有事件循环、观察者、线程池和请求对象等。
首先,我们着重强调一下Node自身的执行模型——事件循环,正是它使得回调函数十分普遍。
在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为Tick。每个Tick的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。流程图如图

在每个Tick的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
这个过程就如同饭馆的厨房,厨房一轮一轮地制作菜肴,但是要具体制作哪些菜肴取决于收银台收到的客人的下单。厨房每做完一轮菜肴,就去问收银台的小妹,接下来有没有要做的菜,如果没有的话,就下班打烊了。
在这个过程中,收银台的小妹就是观察者,她收到的客人点单就是关联的回调函数。当然,如果饭馆经营有方,它可能有多个收银员,就如同事件循环中有多个观察者一样。收到下单就是一个事件,一个观察者里可能有多个事件。
浏览器采用了类似的机制。事件可能来自用户的点击或者加载某些文件时产生,而这些产生的事件都有对应的观察者。在Node中,事件主要来源于网络请求、文件I/O等,这些事件对应的观察者有文件I/O观察者、网络I/O观察者等。观察者将事件进行了分类。
事件循环是一个典型的生产者/消费者模型。异步I/O、网络请求等则是事件的生产者,源源不断为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
请求对象
我们可以先看这张图,大致了解一下node中异步io的实现,然后在看下面的分析。

由于下面的讲解中会引用到内部的一些方法,要记住这些方法是很困难的,所以我建议不必深究这些方法是怎么写的,只要能够弄清楚这张图的流程就好
我们将通过解释Windows下异步I/O(利用IOCP实现)的简单例子来探寻从JavaScript代码到系统内核之间都发生了什么。对于一般的(非异步)回调函数,函数由我们自行调用,如下所示:
1 | var forEach = function (list, callback) { |
对于Node中的异步I/O调用而言,回调函数却不由开发者来调用。那么从我们发出调用后,到回调函数被执行,中间发生了什么呢?事实上,从JavaScript发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,它叫做请求对象。
下面我们以最简单的fs.open()方法来作为例子,探索Node与底层之间是如何执行异步I/O调用以及回调函数究竟是如何被调用执行的:
1 | fs.open = function (path, flags, mode, callback) { |
fs.open()的作用是根据指定路径和参数去打开一个文件,从而得到一个文件描述符,这是后续所有I/O操作的初始操作。从前面的代码中可以看到,JavaScript层面的代码通过调用C++核心模块进行下层的操作。

从JavaScript调用Node的核心模块,核心模块调用C++内建模块,内建模块通过libuv进行系统调用,这是Node里经典的调用方式。这里libuv作为封装层,有两个平台的实现,实质上是调用了uv_fs_open()方法。在uv_fs_open()的调用过程中,我们创建了一个FSReqWrap请求对象。从JavaScript层传入的参数和当前方法都被封装在这个请求对象中,其中我们最为关注的回调函数则被设置在这个对象的oncomplete_sym属性上:
1 | req_wrap->object_->Set(oncomplete_sym, callback); |
对象包装完毕后,在Windows下,则调用QueueUserWorkItem()方法将这个FSReqWrap对象推入线程池中等待执行,该方法的代码如下所示:
1 | QueueUserWorkItem(& uv_fs_thread_proc, req, WT_EXECUTEDEFAULT) |
QueueUserWorkItem()方法接受3个参数:第一个参数是将要执行的方法的引用,这里引用的是uv_fs_thread_proc,第二个参数是uv_fs_thread_proc方法运行时所需要的参数;第三个参数是执行的标志。当线程池中有可用线程时,我们会调用uv_fs_thread_proc()方法。
uv_fs_thread_proc()方法会根据传入参数的类型调用相应的底层函数。以uv_fs_open()为例,实际上调用fs__open()方法。
至此,JavaScript调用立即返回,由JavaScript层面发起的异步调用的第一阶段就此结束。JavaScript线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到JavaScript线程的后续执行,如此就达到了异步的目的。
请求对象是异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。
简单的回答就是:调用fs.open这个方法之后就会获得一个io读取操作,然后把这个操作放入到线程池,等待有空的线程来执行io的读取操作,然后得到结果,将数据传递给回调函数,再执行,再执行回调。
如下图所示。

下面是详细讲解:
组装好请求对象、送入I/O线程池等待执行,实际上完成了异步I/O的第一部分,回调通知是第二部分。
线程池中的I/O操作调用完毕之后,会将获取的结果储存在req->result属性上,然后调用PostQueuedCompletionStatus()通知IOCP,告知当前对象操作已经完成:
1 | PostQueuedCompletionStatus((loop)->iocp, 0, 0, &((req)->overlapped)) |
PostQueuedCompletionStatus()方法的作用是向IOCP提交执行状态,并将线程归还线程池。通过PostQueuedCompletionStatus()方法提交的状态,可以通过GetQueuedCompletionStatus()提取。
在这个过程中,我们其实还动用了事件循环的I/O观察者。在每次Tick的执行中,它会调用IOCP相关的GetQueuedCompletionStatus()方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到I/O观察者的队列中,然后将其当做事件处理。
I/O观察者回调函数的行为就是取出请求对象的result属性作为参数,取出oncomplete_sym属性作为方法,然后调用执行,以此达到调用JavaScript中传入的回调函数的目的。至此,整个异步I/O的流程完全结束。
事件循环、观察者、请求对象、I/O线程池这四者共同构成了Node异步I/O模型的基本要素。
并不是,这些是异步API。
这一部分也值得略微关注一下。
setTimeout()和setInterval()与浏览器中的API是一致的,分别用于单次和多次定时执行任务。它们的实现原理与异步I/O比较类似,只是不需要I/O线程池的参与。调用setTimeout()或者setInterval()创建的定时器会被插入到定时器观察者内部的一个红黑树中。每次Tick执行时,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过,就形成一个事件,它的回调函数将立即执行。

定时器的问题在于,它并非精确的(在容忍范围内)。尽管事件循环十分快,但是如果某一次循环占用的时间较多,那么下次循环时,它也许已经超时很久了。譬如通过setTimeout()设定一个任务在10毫秒后执行,但是在9毫秒后,有一个任务占用了5毫秒的CPU时间片,再次轮到定时器执行时,时间就已经过期4毫秒。
在未了解process.nextTick()之前,很多人也许为了立即异步执行一个任务,会这样调用setTimeout()来达到所需的效果:
1 | setTimeout(function () { |
由于事件循环自身的特点,定时器的精确度不够。而事实上,采用定时器需要动用红黑树,创建定时器对象和迭代等操作,而setTimeout(fn, 0)的方式较为浪费性能。实际上,process.nextTick()方法的操作相对较为轻量,具体代码如下:
1 | process.nextTick = function (callback) { |
每次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的操作时间复杂度为O(lg(n)), nextTick()的时间复杂度为O(1)。相较之下,process.nextTick()更高效。
setImmediate()方法与process.nextTick()方法十分类似,都是将回调函数延迟执行。在Node v0.9.1之前,setImmediate()还没有实现,那时候实现类似的功能主要是通过process.nextTick()来完成,该方法的代码如下所示:
1 | process.nextTick(function () { |
上述代码的输出结果如下:

而用setImmediate()实现时,相关代码如下:
1 | setImmediate(function () { |
其结果完全一样:

但是两者之间其实是有细微差别的。将它们放在一起时,又会是怎样的优先级呢。示例代码如下:
1 | process.nextTick(function () { |
其执行结果如下:

从结果里可以看到,process.nextTick()中的回调函数执行的优先级要高于setImmediate()。这里的原因在于事件循环对观察者的检查是有先后顺序的,process.nextTick()属于idle观察者,setImmediate()属于check观察者。在每一个轮循环检查中,idle观察者先于I/O观察者,I/O观察者先于check观察者。
在具体实现上,process.nextTick()的回调函数保存在一个数组中,setImmediate()的结果则是保存在链表中。在行为上,process.nextTick()在每轮循环中会将数组中的回调函数全部执行完,而setImmediate()在每轮循环中执行链表中的一个回调函数。如下的示例代码可以佐证:
1 | // 加入两个nextTick()的回调函数 |
其执行结果如下:

从执行结果上可以看出,当第一个setImmediate()的回调函数执行后,并没有立即执行第二个,而是进入了下一轮循环,再次按process.nextTick()优先、setImmediate()次后的顺序执行。之所以这样设计,是为了保证每轮循环能够较快地执行结束,防止CPU占用过多而阻塞后续I/O调用的情况。
Puppeteer 是一个 Node 库,它提供了高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。
Puppeteer 翻译过来是傀儡师,操纵提线木偶的人。这里指你可以通过代码操作浏览器,就像用线操纵木偶一样。👉Puppeteer 中文文档
我们可以利用 Puppeteer 实现日常工作自动化,将一些机械性的浏览器操作交给 Puppeteer。
通过 puppeteer.launch 来创建一个浏览器实例。
用 browser.newPage 来创建一个新页面。
页面操作可以通过 page.goto 跳转到指定页面。page.evaluate 在浏览器环境中执行js脚本。browser.close 关闭浏览器。
1 | const browser = await puppeteer.launch({ headless: true }); |
Promise ,执行的时候注意不要异步操作,同时避免 await 某个操作导致卡死。page.waitFor 可以等待某个 dom元素/函数/请求 但是 await 可能很长导致超出30000ms,Puppeteer 抛出异常。page.setJavaScriptEnabled(false) 禁用加载js,以节省加载时间。适用于后台js很多的情况,比如线上 IDE 。但是禁用了以后 evaluate 只能用原生 JavaScript 了。puppeteer.devices 模拟手机访问。参数是数组,例如模拟 iPhone 61 | const iPhone = puppeteer.devices['iPhone 6']; |
持续集成(CI)和持续部署(CD)是DevOps中重要的两个环节,传统的软件开发和交付方式在迅速变得过时。过去的敏捷时代里,大多数公司的软件发布周期是每月、每季度甚至每年,而在现在 DevOps 时代,每周、每天甚至每天多次都是常态。
开发团队通过软件交付流水线(Pipeline)实现自动化,以缩短交付周期,并通过自动化流程来检查代码并部署到新环境。以快速的进行敏捷迭代和开发。
在实际使用中,gitlab的CI/CD是通过开发者预先配置的一系列pipeline参数,通过精心配置的触发时机,在代码提交、合并、或者打tag时,触发自动构建流来完成构建到发布的动作。

我们的任务目标是搭建一个 gitlab + gitlab-runner 的CICD环境,在代码触发时,启动构建动作,构建完毕后将代码推送到应用服务器上进行部署
应用服务是是一个具备nginx的服务,他暴露了80端口允许你访问端口,应用我们选择前端的 hexo 博客系统,开箱即用
为了实现本文档的目标任务,需要做一下软件的前期准备
首先我们在docker安装一个gitlab用来做本次实验
1 | # 下载镜像 |
启动阶段要做较多的初始化工作,需要耐心等待。完成后可以通过 8080 端口看到gilab。

安装好 gitlab 后还要安装 gitlan-runner 并注册,gitlab-runner 主要用于 响应 gitlab CI/CD,CI/CD里面的script脚本将会被 gitlab-runner 所执行
1 | docker pull gitlab/gitlab-runner |
进入容器控制台,输入如下命令进行注册
1 | gitlab-ci-multi-runner register |
注册时需要一个token参数,可以访问 http://localhost/admin/runners 这个页面去获取

1 | > gitlab-ci-multi-runner register |
值得注意的是URL填写的时候,不能使用 https://localhost/ 请使用本机IP, 配置完后页面刷新后你会看到一个新注册的 runner

然后点击编辑,将 lock 那一项给点掉

最后返回列表你会看到

为了能运行nodejs项目,还需要继续安装 nodejs
1 |
|
至此,我们还需要一台用于部署应用的服务器,由于需要使用ssh进行连接(gitlab-runner使用该端口做远程部署),我们使用 nginx 镜像, 并在上面安装一个 openssh-server,最后打开ssh通道,并配置账号密码允许ssh访问
首先,先pull nginx 镜像, 然后启动nginx
1 | docker pull nginx |
启动完毕后,8080端口就可以直接访问了 http://localhost:8080/
至此,runner的执行环境基本做完了,接下来我们需要新建一个代码仓库,然后配置CI/CD的相关内容。
我们需要先创建一个仓库

找到

新建

模板默认已经配好了CICD,可以直接运行
仓库建完后,在仓库目录下面有一个 .gitlab-ci.yml 文件,点开编辑
1 | image: node:10.15.3 |
保存完毕后,CI/CD就开始执行

cicd执行完毕后,由于我们配置了 artifacts 参数,可以在ci/cd面板中下载构建产物
我们可以直接在应用服务器上面下载这个产物 细节看此链接
1 | docker exec -it nginx bash |
命令中的 Ip 请修改成自己的IP,不要使用localhost, root%2Fblog 是项目路径 root/blog encode之后的,PRIVATE-TOKEN 需要在仓库的 Setting -> access token 获得
下载完毕后可以使用 ls 查看
1 | root@6aca3f15f8d8:/usr/share/nginx# ls |
然后我们将其解压
1 |
|

就可以看到结果了(样式问题是工程自己的问题)
todo
1 | # 安装openssh以及文本编辑器 |
修改里面 port 以及 PermitRootLogin

修改完毕后,配置root密码
1 | passwd root |
重新启动sshd
1 | /etc/init.d/ssh restart |
完毕后就可以治用 xshel等软件进行连接

